AIとゲーム理論の融合が導く、サッカープレー評価の最先端研究と未来


「ゲーム理論とAIでサッカー分析の革新に挑戦!」と題したクラウドファンディングが話題になっている。その当事者である3人、AIを用いたサッカーのプレー評価やスポーツに関わるAI技術を研究する名古屋大学の藤井慶輔氏、柏レイソルユース→東大ア式蹴球部出身で自然言語処理の研究を行う大学院生の染谷大河氏、香港科技大学で経済学の研究を行いサッカーへのゲーム理論への適用を構想する川口康平氏の研究グループが、AIを用いたサッカーのプレー評価の最先端研究を解説するとともに、自身のクラウドファンディングのプロジェクトを紹介する。
現代のサッカー界では、映像技術の進歩にもかかわらず、選手のパフォーマンス評価は大量の人力作業に依存しており、多くは映像をベースとした主観的な判断に基づいて行われている。近年の文章生成や画像生成を行うAIの発展からすると、サッカー選手のプレー評価もAIができそうだと一見考えられそうだが、現在はまだ基礎研究の段階である(その理由については後ほど説明する)。
AIを用いたサッカーのプレー評価の現状
サッカーのプレーを自動で評価するために必要なデータは、欧州のトップリーグや日本のJリーグで記録されているパスやシュートなどのイベントデータと、選手全員がいつ・どこにいるかを表すトラッキングデータである。
前者だけでもボールを持つ選手はある程度評価できるが、後者がなければ守備やオフ・ザ・ボールの攻撃選手を評価することが非常に難しい。もしこのようなデータが十分あり、かつAIがサッカーというゲームをモデル化できれば、将棋や囲碁のAIのように一つひとつのプレーが定量的に評価できるようになる可能性が高い。そうなれば、選手やチームの戦術的な動きが、より科学的かつ客観的に評価されるようになるだろう。
AIによるプレー評価が実現すれば、プロのアナリストだけでなく、一般のスポーツファンやアマチュア選手にとっても、どういうプレーが良い・悪いかについて、直感的な理解をもたらし、スポーツの楽しみ方を深め、選手やチームの成長を支援することも期待される。
しかし、サッカーというゲームをモデル化してプレーを正確に評価することは難しい。現在のサッカーの現場でも用いられているゴール期待値(xG)は、出典が複数あり様々な計算方法があるが、基本的には選手全員の位置情報は用いずにボールの位置情報とイベントデータから算出される場合が多く、ゴールの一歩手前のシュートを評価していると理解できる。ちなみに、アシスト期待値(xA)はその一歩手前のパスがどれだけアシストになり得るかを予測して評価するものだ。
ただし、このアプローチではタグ付けされた行動(ゴールやアシスト、インターセプトなど)は予測して評価できるが、タグ付けされない行動(味方のためにスペースを空ける動き、パスを受け取りやすくする動きなど)は評価できない。
この課題を解決するために、今最先端で行われている研究アプローチは2つある。
1つはスペースの評価を行うもので、主に数理モデルをベースに、オフ・ザ・ボールの選手、あるいは守備の選手がどこにいるべきかを計算して評価するアプローチである(図1)。
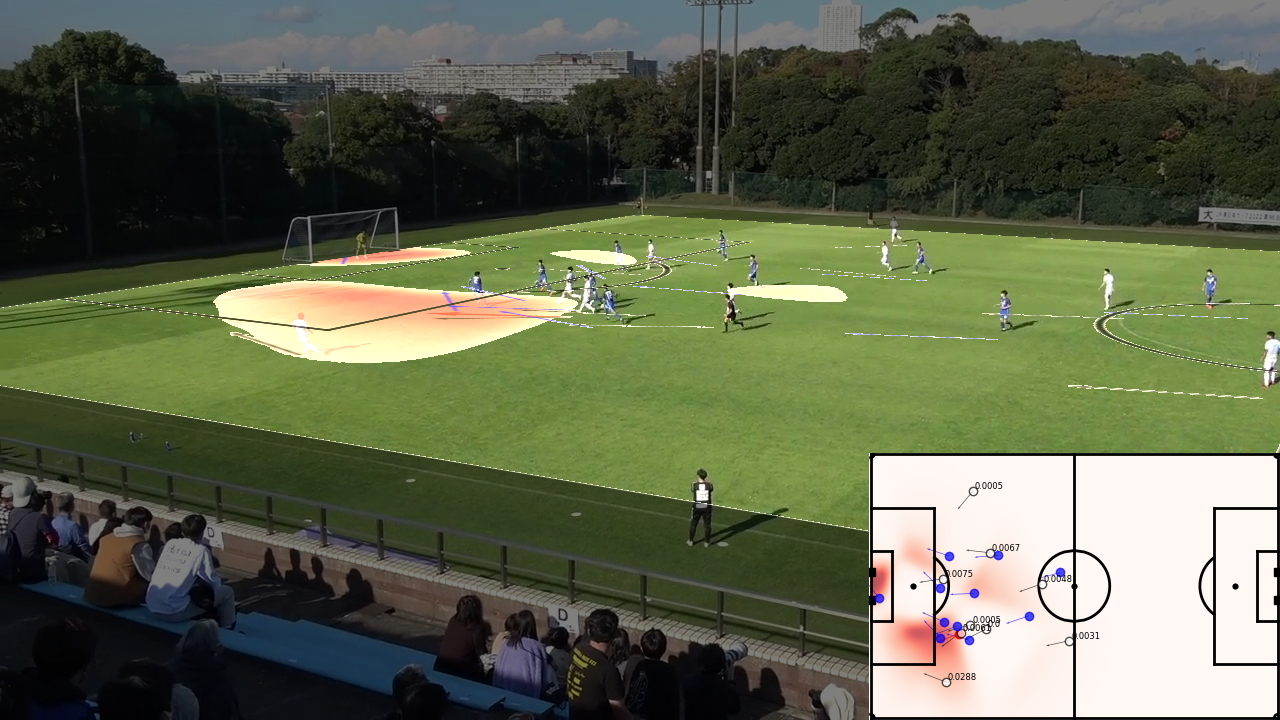
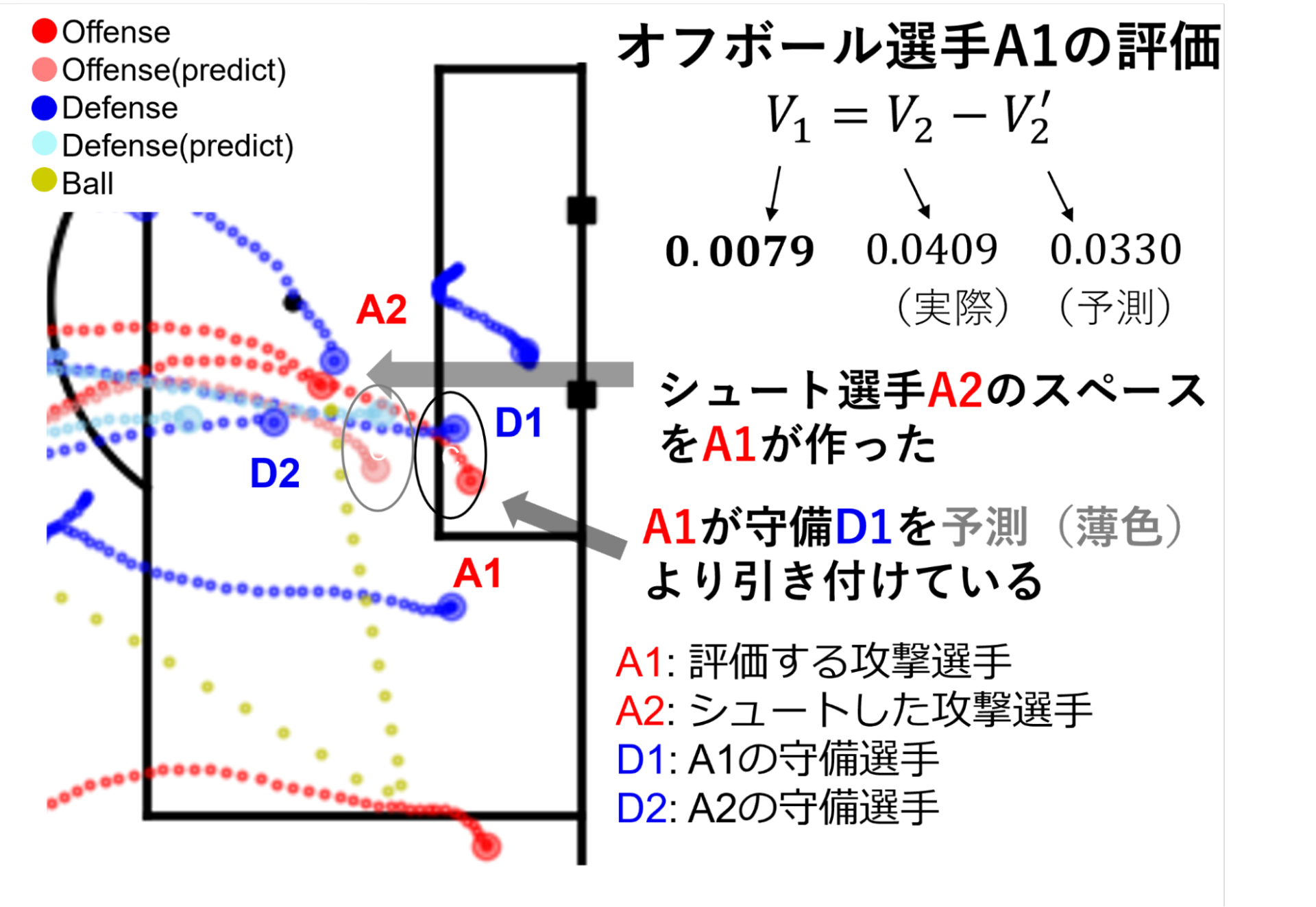
例えば、どの場所だとどのチームがボールを保持できるかという占有率、次のイベントでボールがどこに移動しているかを予測する遷移率、シュートをどこで打てば得点が入りそうかという得点率をかけ合わせたOBSO(Off-ball Scoring Opportunity)[1] という「次にどこにパスを出したら得点が入りそうか」を示す指標がある。例えば、当時の大学院生の寺西と藤井らは、これを応用して機械学習による軌道予測を基準として、「基準と比べてどのくらい味方の得点機会の増加に貢献したか」を定量化することで、「味方のためにスペースを空ける動き」を評価することに成功した [2](図2)。
もう1つのアプローチは、報酬を得るために行動するエージェントとして選手をモデル化する強化学習という方法である(図3)。サッカーにおける強化学習の研究というと、2020年に発表されたGoogle Research Football(GFootball)[3] が画期的であった。Pythonで簡単に強化学習アルゴリズムを試せるプラットフォームを公開したことで、その後、機械学習のトップ国際会議でも、続々と強化学習アルゴリズムの研究が発表されている。ボードゲームと異なり、連続的な空間で自由に動けるエージェントが22人もいるため、11対11はまだ学習が難しい状況だが、3対1や4対2などの問題設定を作ったり、テレビゲームのような離散的な行動を定義することで、問題にチャレンジしやすくなっている。
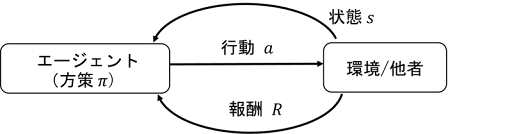
ただし、これまでスポーツのデータ解析を中心に研究してきた藤井らは、このようなエージェントモデルを使って、実際の選手の取った行動を評価できないか、と考えた [4]。これまでにも、強化学習の枠組みを用いて実際の集団スポーツの選手の動きを評価する研究は存在し [5,6]、例えば行動ごとに価値を算出できる関数(Q関数)を推定することで、シュートやパスなどのボールに対するアクションを評価していた。しかし、チームを単一のエージェントとして考慮することが多く、すべての時間ステップでオフ・ザ・ボールの選手まで評価できない。
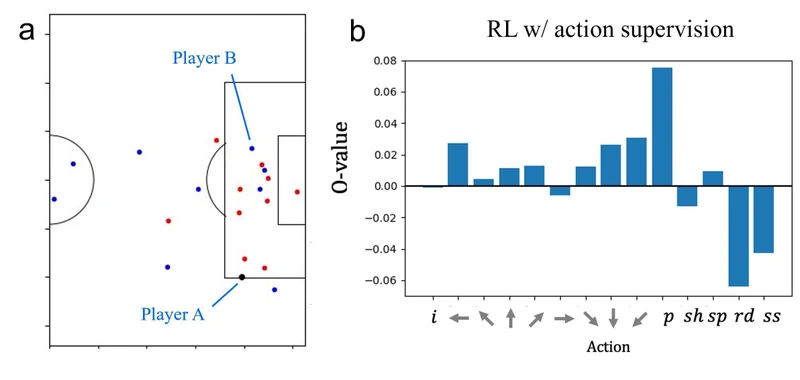
そこで、当時の大学院生の中原と藤井らは、下記のような行動ごとの価値(Q値)を推定するための、ゴールなどの単純な報酬に基づく深層強化学習モデルを考えた [4]。離散的な行動として、GFootballを模して8方向の移動や、シュート(sh)やパス(p)などをアクションとして定義して、冒頭の画像にあるように、それぞれの行動の価値(Q値)を出力するニューラルネットワークを考えた。
結果の例として、選手Aがボールを持ち、選手Bにパスするシーンで、各行動(横軸)に対する価値(Q値)を計算した(図4)。この例では、パス(p)のQ値が最も大きい、つまりパスが最も効果的であると評価したことを示す。この研究は、初めての試みとして非常に単純なパラメータ設定にて検証を行ったが、より正確にモデル化を行うことで、より精度の高い評価が行える可能性が期待できる。
「逆強化学習」と「ゲーム理論」で意思決定の質を評価する
その発展として考えているのが、現在クラウドファンディングを行っている「逆強化学習」と「ゲーム理論」の導入により選手のプレー精度や意思決定の質まで評価する方法を開発するプロジェクトである。
「逆強化学習」と中原らの「強化学習」の研究との大きな違いは、選手が何を考えてプレーしているのかを、ゴールなどの研究者が考えた報酬に基づいて計算するのではなく、データから推定する点にある。
……


Profile
藤井 慶輔/染谷 大河/川口 康平
【藤井 慶輔】名古屋大学大学院情報学研究科 准教授。主にスポーツ科学と機械学習の研究に従事し、両領域での論文や受賞多数。京都大学にて博士号取得後(人間・環境学)、日本学術振興会特別研究員PDと理化学研究所革新知能統合研究センター研究員を経て、現在に至る。【染谷 大河】東京大学大関研究室 修士2年。主に自然言語処理分野の研究に従事し、最難関国際会議にも論文採択。近年は、サッカーにおける深層学習技術の応用研究も行う。未踏クリエイタ。柏レイソルU-18出身、元U-15/16日本代表候補。【川口 康平】香港科技大学商学院経済学部助理教授。ロンドン・スクール・オブ・エコノミクスPhD(経済学)。主に産業組織論とマーケティングにおける企業や消費者の意思決定に関わる実証研究に従事し、両領域での論文多数。一橋大学経済学研究科勤務を経て、現在に至る。
関連記事











